acdc_rede_emocoes.pl -c TODOS acdc_rede_emocoes.pl -c LITERATECAque criam, usando as ferramentas do Open CWB, os seguintes ficheiros de dados: matrizTODOS, matrizmatrizTODOS.R e lexicoTODOS, e matrizLITERATECA, matrizmatrizLITERATECA e lexicoLITERATECA.
Depois executa-se, para limpar
grep -v TE lexicoTODOS | grep -v DESAP | grep -v cjt > lexicoEmosTodos.R grep -v TE lexicoLITERATECA | grep -v DESAP | grep -v cjt > lexicoEmosLiterateca.Re para calcular os pesos, que se refletem na espessura dos arcos que juntam as emoções
acdc_igraph_calcula_pesos.pl < lexicoEmosTodos.R > comEmosTodosPesos acdc_igraph_calcula_pesos.pl < lexicoEmosTodos.R > comEmosLiteratecaPesosPara fazer as figuras da coocorrência, no R: Todos, Literateca
require(igraph)
lista<-read.table("matrizTODOS")
G<-graph_from_edgelist(as.matrix(subset(lista,TRUE,1:2)), directed=FALSE)
E(G)$weight <- lista$V3
source("comEmosTodosPesos")
png("emosTodos.png", width = 5, height = 5, units = 'in', res=300)
par(mar=c(0.5,0.5,0.5,0.5)+0.1)
plot(G, layout=layout.random, edge.width=20*E(G)$weight/max(E(G)$weight))
dev.off()
lista<-read.table("matrizLITERATECA")
G<-graph_from_edgelist(as.matrix(subset(lista,TRUE,1:2)), directed=FALSE)
E(G)$weight <- lista$V3
source("comEmosLiteratecaPesos")
png("emosLit.png", width = 5, height = 5, units = 'in', res=300)
par(mar=c(0.5,0.5,0.5,0.5)+0.1)
plot(G, layout=layout.random, edge.width=20*E(G)$weight/max(E(G)$weight))
dev.off()
Para obter os grafos das palavras de um dado grupo de emoção, cria-se primeiro no CQP os léxicos
TODOS> set as off; TODOS> [sema=".*emo:amor.*"]; TODOS> group Last match lema > "listaLemasAmorTodos" TODOS> [sema=".*emo:desespero.*"] TODOS> group Last match lema > "listaLemasDesesperoTodos" LITERATECA> [sema=".*emo:amor.*"]; LITERATECA> group Last match lema > "listaLemasAmorLit" LITERATECA> [sema=".*emo:desespero.*"]; LITERATECA> group Last match lema > "listaLemasDesesperoLit"e editam-se para ficarem na forma palTABfreq, e melhora-se com
cat listaLemasAmorTodos | acdc_melhora_lista_freq_lemas.pl > listaAmorIni acdc_igraph_calcula_pesos.pl < listaAmorIni > comAmorTodosPesos iconv -f iso-8859-1 -t utf8 comAmorTodosPesos > comAmorTodosPesos.R cat listaLemasDesesperoTodos | acdc_melhora_lista_freq_lemas.pl > listaDesesperoIni acdc_igraph_calcula_pesos.pl < listaDesesperoIni > comDesesperoTodosPesos iconv -f iso-8859-1 -t utf8 comDesesperoTodosPesos > comDesesperoTodosPesos.RArranjam-se os ficheiros listaDesespero e listaAmor, editados a partir da procura no AC/DC.
acdc_rede_emocoes_palavras.pl -c LITERATECA -f Desespero acdc_rede_emocoes_palavras.pl -c LITERATECA -f Amor acdc_rede_emocoes_palavras.pl -c TODOS -f Desespero acdc_rede_emocoes_palavras.pl -c TODOS -f Amorque criam os ficheiros matrizTODOSAmor, matrizmatrizTODOSAmor.R, matrizTODOSDesespero, matrizmatrizTODOSDesespero.R, matrizLITERATECAAmor, matrizmatrizLITERATECAAmor.R, matrizLITERATECADesespero e matrizmatrizLITERATECADesespero.R.
iconv -f iso-8859-1 -t utf8 matrizTODOSAmor > matrizTodosAmor.R iconv -f iso-8859-1 -t utf8 matrizmatrizTODOSAmor.R > matrizmatrizTodosAmor.R iconv -f iso-8859-1 -t utf8 matrizTODOSDesespero > matrizTodosDesespero.R iconv -f iso-8859-1 -t utf8 matrizmatrizTODOSDesespero.R > matrizmatrizTodosDesespero.R iconv -f iso-8859-1 -t utf8 matrizLITERATECAAmor > matrizLitAmor.R iconv -f iso-8859-1 -t utf8 matrizmatrizLITERATECAAmor.R > matrizmatrizLitAmor.R iconv -f iso-8859-1 -t utf8 matrizLITERATECADesespero > matrizLitDesespero.R iconv -f iso-8859-1 -t utf8 matrizmatrizLITERATECADesespero.R > matrizmatrizLitDesespero.RNo R, para obter as figuras amorTodos.png, amorLit.png, desesperoTodos.png e desesperoLit.png.
require(igraph)
lista<-read.table("matrizTodosAmor.R")
G<-graph_from_edgelist(as.matrix(subset(lista,TRUE,1:2)), directed=FALSE)
E(G)$weight <- lista$V3
source("comAmorTodosPesos.R")
png("amorTodos.png", width = 5, height = 5, units = 'in', res=300)
par(mar=c(0.5,0.5,0.5,0.5)+0.1)
plot(G, layout=layout.random, edge.width=20*E(G)$weight/max(E(G)$weight))
dev.off()
lista<-read.table("matrizLitAmor.R")
G<-graph_from_edgelist(as.matrix(subset(lista,TRUE,1:2)), directed=FALSE)
E(G)$weight <- lista$V3
source("comAmorLitPesos.R")
png("amorLit.png", width = 5, height = 5, units = 'in', res=300)
par(mar=c(0.5,0.5,0.5,0.5)+0.1)
plot(G, layout=layout.random, edge.width=20*E(G)$weight/max(E(G)$weight))
dev.off()
lista<-read.table("matrizTodosDesespero.R")
G<-graph_from_edgelist(as.matrix(subset(lista,TRUE,1:2)), directed=FALSE)
E(G)$weight <- lista$V3
source("comDesesperoTodosPesos.R")
png("desesperoTodos.png", width = 5, height = 5, units = 'in', res=300)
par(mar=c(0.5,0.5,0.5,0.5)+0.1)
plot(G, layout=layout.random, edge.width=20*E(G)$weight/max(E(G)$weight))
dev.off()
lista<-read.table("matrizLitDesespero.R")
G<-graph_from_edgelist(as.matrix(subset(lista,TRUE,1:2)), directed=FALSE)
E(G)$weight <- lista$V3
source("comDesesperoLitPesos.R")
png("desesperoLit.png", width = 5, height = 5, units = 'in', res=300)
par(mar=c(0.5,0.5,0.5,0.5)+0.1)
plot(G, layout=layout.random, edge.width=20*E(G)$weight/max(E(G)$weight))
dev.off()
Para fazer o agrupamento geral, resultando nas figuras todosmds.png e todos3mds.png
matTodos<-read.table("matrizmatrizTODOS.R", row.names=1)
matTodos<-matTodos+0.00001
tamanhoEmo<-read.table("lexicoEmosTodos.R",row.names=1)
colnames(tamanhoEmo)<-"tam"
matTodosNovo=matrix(nrow=26,ncol=26)
colnames(matTodosNovo)<-colnames(matTodos)
rownames(matTodosNovo)<-rownames(matTodos)
for (i in 1:26) {
print (i);
for (j in 1:26) {
print(rownames(matTodos)[i]);
print(colnames(matTodos)[j]);
print (tamanhoEmo$tam[i]);
print (tamanhoEmo$tam[j]);
print (min(tamanhoEmo$tam[i],tamanhoEmo$tam[j]));
print (matTodos[i,j]/min(tamanhoEmo$tam[i],tamanhoEmo$tam[j]));
matTodosNovo[i,j]<-matTodos[i,j]/min(tamanhoEmo$tam[i],tamanhoEmo$tam[j])
}
}
for (i in 1:26) {
for (j in 1:26) {
matTodosNovo[i,j]<-matTodos[i,j]/min(tamanhoEmo$tam[i],tamanhoEmo$tam[j])
}
}
matTodos<-matTodosNovo
nmat<-1/matTodos
emosTodos.dist<-as.dist(nmat)
emosTodos2dim.mds<-cmdscale(emosTodos.dist, k=2)
ola<-data.frame(emosTodos2dim.mds)
png("todosmds.png", height=6, width=8, units="in", res=300)
plot(ola$X1,ola$X2, type="n", xlab="dimension 1", ylab="dimension 2",main="Multidimensional scaling of emotion groups by co-occurrence")
text(ola$X1,ola$X2, row.names(ola))
dev.off()
emosTodos3dim.mds<-cmdscale(emosTodos.dist, k=3)
ola<-data.frame(emosTodos3dim.mds)
png("todos3mds.png", height=8, width=8, units="in", res=300)
plot(ola$X2,ola$X3, type="n", xlab="dimension 2", ylab="dimension 3",main="Multidimensional scaling of emotion groups by co-occurrence")
text(ola$X2,ola$X3, row.names(ola))
dev.off()
Para criar os dendogramas, no ficheiro clustTodos2met.png
png("clustTodos.png")
plot(hclust(emosTodos.dist,method="ward.D2"))
dev.off()
png("clustTodos2met.png", height=10,width=30,units="cm", res=1000)
par(mfrow=c(1,2))
plot(hclust(emosTodos.dist,method="complete"),main="Method: complete")
plot(hclust(emosTodos.dist,method="ward.D2"),main="Method: ward.D2")
dev.off()
Mais agrupamento
matTodosAmor<-read.table("matrizmatrizTodosAmor.R", row.names=1)
amorTodos<-as.dist(1/(matTodosAmor+.00001))
plot(hclust(amorTodos))
Multidimensional scaling, nos ficheiros mds3AmorTodos.png e mds3DesesperoTodos.png
library(languageR)
matriz <- read.table("matrizmatrizLitDesespero.R",row.names=1)
matriz <- matriz +0.00001
nmat<- 1/matriz
emos.dist<-as.dist(nmat)
emos2dim.mds<-cmdscale(emos.dist, k=2)
ola<-data.frame(emos2dim.mds)
plot(ola$X1,ola$X2, type="n", xlab="dimension 1", ylab="dimension 2",main="Multidmensional scaling of emotion groups by co-occurrence")
text(ola$X1,ola$X2, row.names(ola))
emos3dim.mds<-cmdscale(emos.dist, k=3)
ola<-data.frame(emos3dim.mds)
png("mds3DesesperoTodos.png", height=10,width=30,units="cm", res=1000)
par(mfrow=c(1,3))
plot(ola$X1,ola$X2, type="n", xlab="dimension 1", ylab="dimension 2")
text(ola$X1,ola$X2, row.names(ola))
plot(ola$X1,ola$X3, type="n", xlab="dimension 1", ylab="dimension 3")
text(ola$X1,ola$X3, row.names(ola))
plot(ola$X2,ola$X3, type="n", xlab="dimension 2", ylab="dimension 3")
text(ola$X2,ola$X3, row.names(ola))
dev.off()
matriz <- read.table("matrizmatrizLitAmor.R",row.names=1)
matriz <- matriz +0.00001
nmat<- 1/matriz
emos.dist<-as.dist(nmat)
emos3dim.mds<-cmdscale(emos.dist, k=3)
ola<-data.frame(emos3dim.mds)
png("mds3AmorTodos.png", height=10,width=30,units="cm", res=1000)
par(mfrow=c(1,3))
plot(ola$X1,ola$X2, type="n", xlab="dimension 1", ylab="dimension 2")
text(ola$X1,ola$X2, row.names(ola))
plot(ola$X1,ola$X3, type="n", xlab="dimension 1", ylab="dimension 3")
text(ola$X1,ola$X3, row.names(ola))
plot(ola$X2,ola$X3, type="n", xlab="dimension 2", ylab="dimension 3")
text(ola$X2,ola$X3, row.names(ola))
dev.off()
word2vec -train emoword -output emoword.vec -cbow 1 -size 300 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -binary 0 -iter 50Usando depois, em python, com a biblioteca KeyedVectors do gensim, o programa model.most_similar (com o parâmetro topn=50), criam-se os ficheiros word-scores.csv, groups-scores.csv, word-and-groups-scores.csv e same_group.csv.
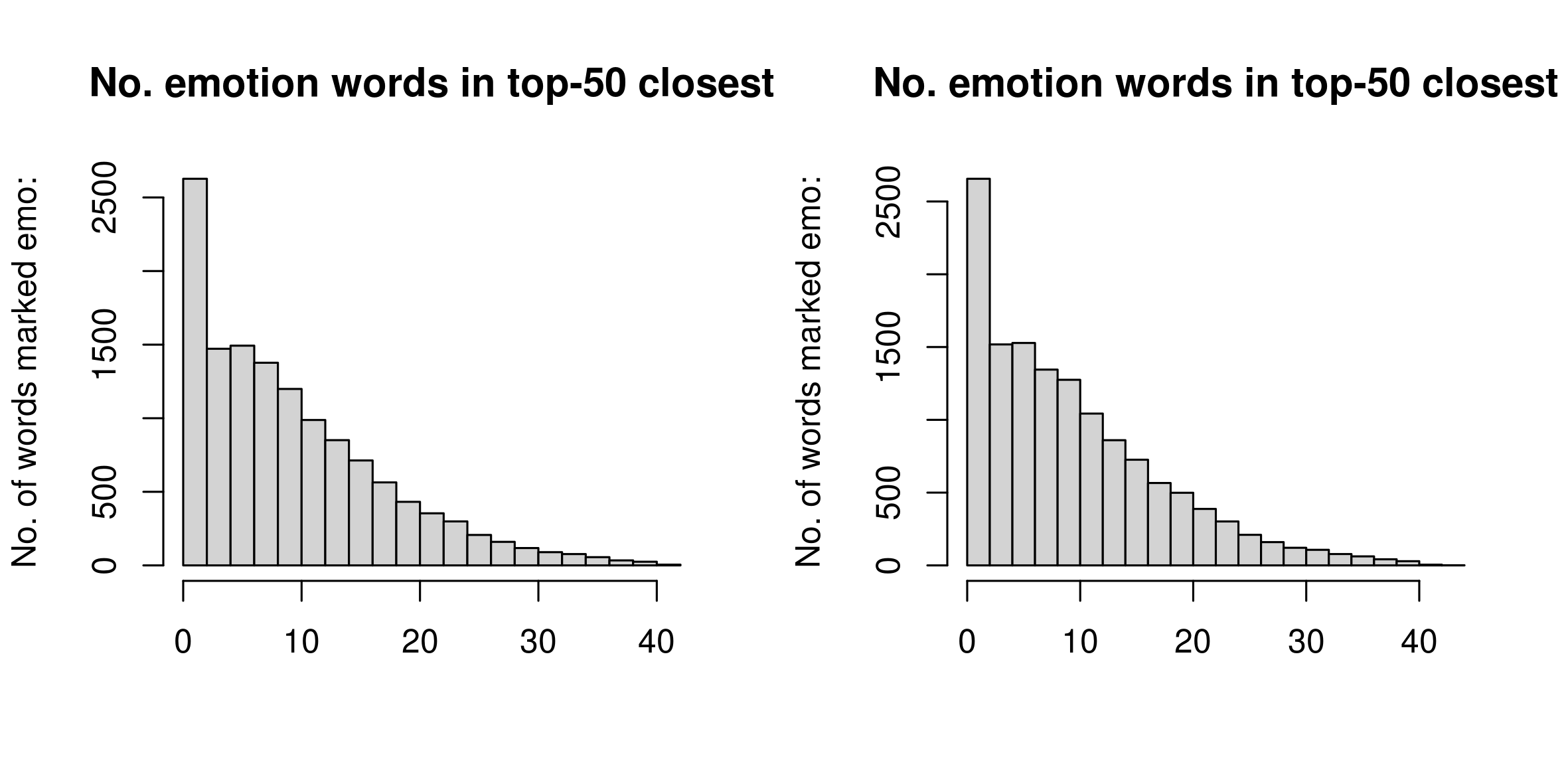
Para fazer o histograma dos números em 50, histquantas.png
emos<-read.table("word-scores.csv")
names(emos)<-c("palavra", "posicao", "numeroem50", "ranking")
boxplot(emos$ranking)
emos3<-read.table("word-and-groups-scores.csv")
names(emos3)<-c("palavra", "posicao", "numeroem50", "ranking", "maisprox")
boxplot(emos3$ranking)
png("histquantas.png",height=10,width=20,units="cm", res=300)
par(mfrow=c(1,2))
hist(emos$numeroem50, breaks=20, main="No. emotion words in top-50 closest",xlab="",ylab="No. of words marked emo:")
hist(emos3$numeroem50,breaks=20, main="No. emotion words in top-50 closest",xlab="",ylab="No. of words marked emo:")
dev.off()
Para ver a correlação entre a frequência das emoções e o número de emoções
freqs<-read.table("emo-list.txt")
names(freqs)<-c("freq","palavra")
total<-merge(emos,freqs)
hist(total[total$freq>10,]$numeroem50)
attach(total)
cor.test(numeroem50,freq)
Para ver o caso do mesmo grupo, samegroup.png
grupos<-read.table("groups-scores.csv")
names(grupos)<-c("grupo", "posicao", "numeroem50", "ranking")
freqg<-read.table("groups-counts.txt")
names(freqg)<-c("freq","grupo")
totalg<-merge(grupos,freqg)
mesmogrupo<-read.table("same_group.csv")
names(mesmogrupo)<-c("palavra","mesmo")
total3<-merge(mesmogrupo, emos3)
png("samegroup.png",height=10,width=20,units="cm", res=300)
hist(total3$mesmo/total3$numeroem50,xlab="% of close emotions from the same group", main="Histogram of % of close emotions from the same group" )
dev.off()
Última atualização desta página: 7 de setembro de 2022.
{kind=link}