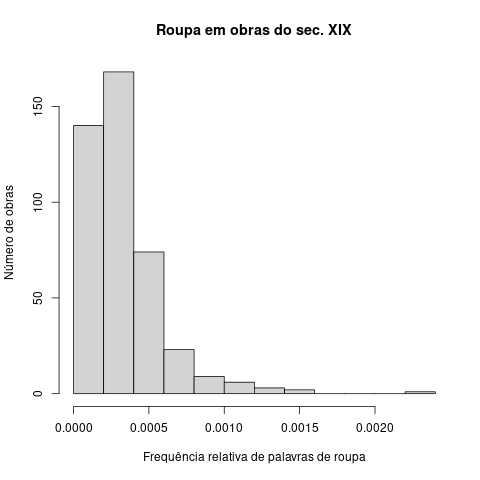
roupa<-read.table("roupaSecXIX.R")
colnames(roupa)<-c("obra","roupa","tamanho")
roupa$rouparel<-roupa$roupa/roupa$tamanho
hist(roupa$rouparel, main="Roupa em obras do sec. XIX", ylab="Número de obras", xlab="Frequência relativa de palavras de roupa")
?decada=/^1[89].*/ ?variante=/(PT|BR)/ obra variante sexo decada
Depois, no R, precisamos de adicionar uma característica chamada século, calculada a partir da década:
seculo<-function(x) {
trunc((x-1801)/100)+19}
obradecada<-read.table("distobravariantesexodecada.tsv")
colnames(obradecada)<-c("obra","tamanho","variante","sexo","decada","lixo","lixo")
obradecada$decada<-as.numeric(as.character(obradecada$decada))
obradecada$seculo<-seculo(obradecada$decada)
mosaicplot(~sexo+variante+seculo,data=obradecada)
mosaicplot(~seculo+sexo+variante,data=obradecada, main="Obras brasileiras e portuguesas dos séculos XIX e XX")

juldin<-read.table("emosJulDin.R")
colnames(dinis)<-c("emo","quant")
pie(dinis$quant, labels=dinis$emo, main="Paleta emocional de Júlio Dinis")
Para colocar seis numa mesma figura
par(mfrow=c(2,3)
etc
Procura: [autor="CamCBra" & classe="Prosa:romance.*" & sema=".*amor.*"] Distribuição de obra Procura: [autor="CamCBra" & classe="Prosa:romance.*" & sema=".*odio.*"] Distribuição de obra Procura: [autor="MacAss" & classe="Prosa:(romance|novela).*" & sema=".*odio.*"] Distribuição de obra ...e depois eventualmente juntar no R se quiséssemos, ou fazer um diagrama de caixa de cada, garantindo, para comparar visualmente, que todas as figuras tinham os mesmos limites no eixo dos YY
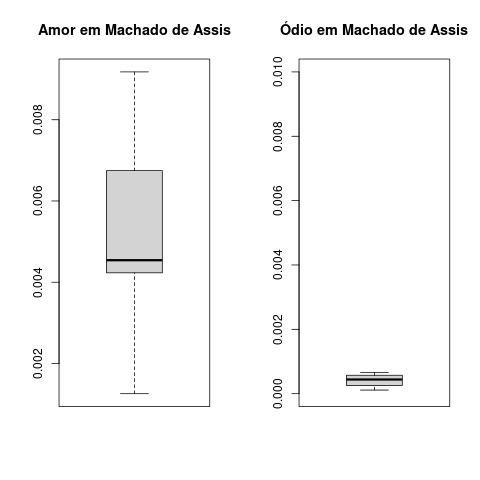
amorMA<-read.table("amorMacAss.R")
colnames(amorMA)<-c("obra","amor","tamanho")
amorMA$amorrel<-amorMA$amor/amorMA$tamanho
boxplot(amorMA$amorrel,main="Amor em Machado de Assis")
odioMA<-read.table("odioMacAss.R")
colnames(odioMA)<-c("obra","odio","tamanho")
odioMA$odiorel<-odioMA$odio/odioMA$tamanho
boxplot(odioMA$odiorel,ylim=c(0,.01), main="Ódio em Machado de Assis")
Mas se quiséssemos fazer para muitos autores, ou para muitas emoções, seria mais eficiente obter tudo ao mesmo tempo usando o distribuidor:
?sema=/.*(amor|odio).*/ ?autor=/(CamCBra|MacAss)/ ?classe=/Prosa:romance/ obra sema ?autor=/CamCBra|MacAss/ obra autorE tentar processar o resultado no R
amorodio<-read.table("distamorodio2autores2.tsv")
colnames(amorodio)<-c("obra", "lixo", "emoexata", "emos","lixo")
amorodio$obra<-factor(amorodio$obra)
obras<-read.table("tamobraautor.tsv")
colnames(obras)<-c("obra","tamanho","autor","lixo","lixo")
obras$obra<-factor(obras$obra)
obras$autor<-factor(obras$autor)
emosobras<-merge(amorodio,obras,by.x=c("obra"), by.y=c("obra"))
emoobra<-emosobras[,c("obra","tamanho", "emoexata","autor", "emos")]
emoobra$emorel<-emoobra$emos/emoobra$tamanho
emoobra$emo<-"0"
emoobra[grep("amor", as.character(emoobra$emoexata), perl=TRUE),]$emo<-"amor"
emoobra[grep("odio", as.character(emoobra$emoexata), perl=TRUE),]$emo<-"odio"
attach(emoobra)
boxplot(emorel~autor+emo)
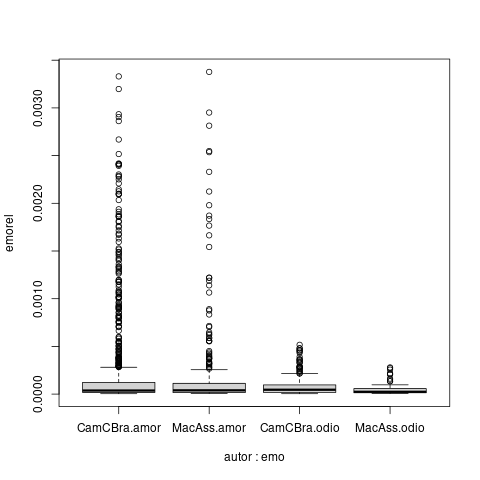
( Nota: ainda é preciso somar os casos de amor e ódio por obra, não tive tempo.)
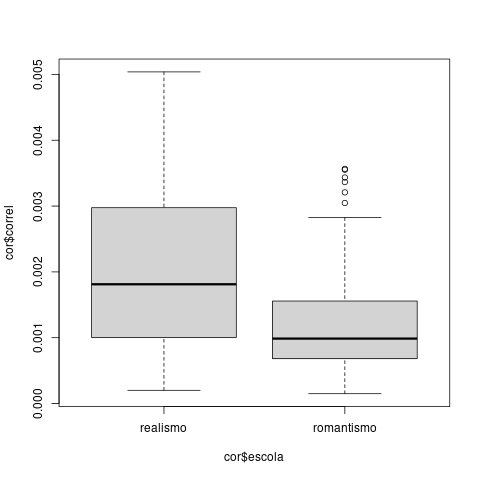
Procura: [escola=".*realismo.*" & escola!=".*romantismo.*" & sema="cor"] Distribuição de obra Procura: [escola=".*romantismo.*" & escola!=".*realismo.*" & sema="cor"] Distribuição de obraNo R
cor<-read.table("corescola.R")
colnames(cor)<-c("obra","cores","tamanho","escola")
cor$obra<-factor(cor$obra)
cor$escola<-factor(cor$escola)
cor$correl<-cor$cores/cor$tamanho
boxplot(cor$correl~cor$escola)
t.test(cor$correl~cor$escola)
A diferença é significativa com um valor p de 4.804e-05.