Um dos objectivos destas modificações no processo foi ter um maior número de resultados revistos, o que não impede que, iterativamente, e mesmo com um horizonte temporal posterior às próprias Morfolimpíadas, se possa ir obtendo classificações até ao limite de ter todas as unidades analisadas.
Como resultado, obtivemos 380 formas revistas por quatro a seis pessoas diferentes (e sempre revistas pelo Paulo, Luís Costa e Diana), que foram enviadas aos participantes e à comissão científica a 19 de Maio de 2003.
Com essas formas obtiveram-se os textos distribuídos aos participantes.
Obteve-se, além disso, também um conjunto de casos específicos para escrutínio (que não foi, contudo levado em conta para avaliação na própria comparação, por falta de tempo)
Adicionalmente procura-se ter alguma aleatoriedade na escolha das formas : embora se comece pelas palavras com maior divergência nas análises, este não é o único critério para uma palavra entrar na lista prateada. Para cada palavra candidata é feito um "sorteio" que determina se a palavra entra ou não na lista prateada.
Para medir a divergência entre as análises de uma determinada forma pelos diferentes sistemas temos uma função que "conta" divergências. Para tal compara o conjunto da análises da forma por um sistema com os conjuntos de análises da forma por todos os outros sistemas um a um. O resultado da função de divergência "global" é o resultado da soma das funções de divergência entre os sistemas um a um.
A função de cálculo de divergência entre dois sistemas, conta o número de análises da forma por um sistema que não são contempladas pelo outro sistema e vice versa. Para determinar se uma análise de um sistema está contemplada noutro sistema, usamos uma função de comparação que verifica a equivalência de todos os campos dos ficheiros de saída, exceptuando o campo "outros" que por definição é utilizado para colocar informação específica de cada um dos sistemas.
Dada a saída dos sistemas, pretendemos criar, além disso (ainda não foi efectuado):
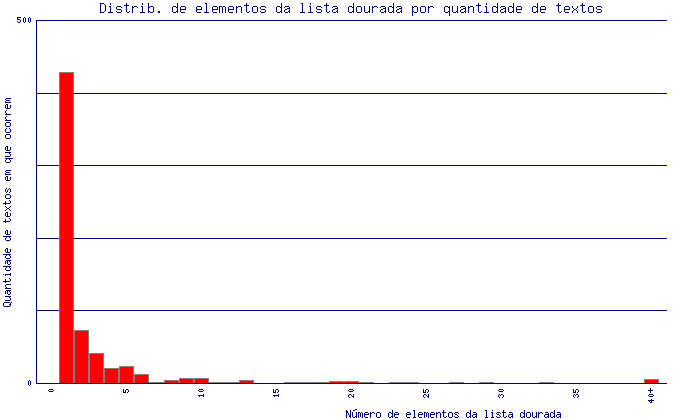
Aqui pretendemos mostrar informação quantitativa pormenorizada das várias "peças" contidas na lista dourada. A própria lista dourada encontra-se aqui completa, e separada nas três fases (fase 1, fase 2 e fase 3).
| Sistema | Dourada Total | % | Dourada1 | % | Dourada2 | % | Dourada3 | % |
| Unidades identificadas | 655 | 100.00% | 380 | 100.00% | 131 | 100.00% | 144 | 100.00% |
| Unidades classificadas como erro (X) | 19 | 2.90% | 15 | 3.95% | 3 | 2.29% | 1 | 0.69% |
| Lexicais | 652 | 99.54% | 379 | 99.74% | 131 | 100.00% | 142 | 98.61% |
| Lexicais sem hífen | 622 | 94.96% | 351 | 92.37% | 129 | 98.47% | 142 | 98.61% |
| Lexicais com hífen | 30 | 4.58% | 28 | 7.37% | 2 | 1.53% | 0 | 0.00% |
| Numéricas | 2 | 0.31% | 0 | 0.00% | 0 | 0.00% | 2 | 1.39% |
| Lexicais com pontuação | 1 | 0.15% | 1 | 0.26% | 0 | 0.00% | 0 | 0.00% |
| Unidades lexicais simples | 655 | 100.00% | 380 | 100.00% | 131 | 100.00% | 144 | 100.00% |
| Siglas | 5 | 0.76% | 3 | 0.79% | 2 | 1.53% | 0 | 0.00% |
| Formas com análise SUB | 409 | 62.44% | 249 | 65.53% | 89 | 67.94% | 71 | 49.31% |
| Formas com análise V | 297 | 45.34% | 168 | 44.21% | 52 | 39.69% | 77 | 53.47% |
| Formas com análise V+CL | 16 | 2.44% | 15 | 3.95% | 1 | 0.76% | 0 | 0.00% |
| Formas com análise ADJ | 257 | 39.24% | 142 | 37.37% | 57 | 43.51% | 58 | 40.28% |
| Formas com análise ADV | 27 | 4.12% | 20 | 5.26% | 2 | 1.53% | 5 | 3.47% |
| Formas com análise NUM | 11 | 1.68% | 5 | 1.32% | 1 | 0.76% | 5 | 3.47% |
| Formas com análise PROP | 44 | 6.72% | 18 | 4.74% | 14 | 10.69% | 12 | 8.33% |
| Formas com análise INTERJ | 16 | 2.44% | 10 | 2.63% | 2 | 1.53% | 4 | 2.78% |
| Formas com análise GRAM | 24 | 3.66% | 18 | 4.74% | 3 | 2.29% | 3 | 2.08% |
| Formas com análises derivadas | 81 | 12.37% | 36 | 9.47% | 9 | 6.87% | 36 | 25.00% |
| Formas com análises de contracção | 6 | 0.92% | 4 | 1.05% | 2 | 1.53% | 0 | 0.00% |
| Formas com análises da variante lus | 24 | 3.66% | 12 | 3.16% | 1 | 0.76% | 11 | 7.64% |
| Formas com análises da variante bras | 60 | 9.16% | 39 | 10.26% | 8 | 6.11% | 13 | 9.03% |
| Formas com análises raras | 76 | 11.60% | 50 | 13.16% | 9 | 6.87% | 17 | 11.81% |
| Formas com uma análise | 210 | 32.06% | 123 | 32.37% | 45 | 34.35% | 42 | 29.17% |
| Formas com duas análises | 236 | 36.03% | 139 | 36.58% | 49 | 37.40% | 48 | 33.33% |
| Formas com três análises | 96 | 14.66% | 55 | 14.47% | 20 | 15.27% | 21 | 14.58% |
| Formas com quatro análises | 80 | 12.21% | 40 | 10.53% | 15 | 11.45% | 25 | 17.36% |
| Formas com mais de quatro análises | 33 | 5.04% | 23 | 6.05% | 2 | 1.53% | 8 | 5.56% |
| Formas com ambiguidade SUB/ADJ | 155 | 23.66% | 95 | 25.00% | 26 | 19.85% | 34 | 23.61% |
| Formas com ambiguidade SUB/ADV | 10 | 1.53% | 7 | 1.84% | 1 | 0.76% | 2 | 1.39% |
| Formas com ambiguidade SUB/V | 144 | 21.98% | 93 | 24.47% | 23 | 17.56% | 28 | 19.44% |
| Formas com ambiguidade SUB/SUB | 75 | 11.45% | 52 | 13.68% | 9 | 6.87% | 14 | 9.72% |
| Formas com ambiguidade V/V | 157 | 23.97% | 88 | 23.16% | 23 | 17.56% | 46 | 31.94% |
| Formas com ambiguidade V/ADJ | 92 | 14.05% | 60 | 15.79% | 14 | 10.69% | 18 | 12.50% |
| Formas com ambiguidade ADJ/ADJ | 45 | 6.87% | 20 | 5.26% | 9 | 6.87% | 16 | 11.11% |
| Formas com ambiguidade ADV/ADV | 9 | 1.37% | 6 | 1.58% | 1 | 0.76% | 2 | 1.39% |
| Formas com ambiguidade ADJ/ADV | 9 | 1.37% | 8 | 2.11% | 0 | 0.00% | 1 | 0.69% |
| Formas com ambiguidade GRAM/outro | 21 | 3.21% | 16 | 4.21% | 2 | 1.53% | 3 | 2.08% |
| Análises como V | 509 | 34.46% | 272 | 31.89% | 79 | 28.83% | 158 | 45.14% |
| Análises como V+CL | 22 | 1.49% | 21 | 2.46% | 1 | 0.36% | 0 | 0.00% |
| Análises como SUB | 487 | 32.97% | 301 | 35.29% | 100 | 36.50% | 86 | 24.57% |
| Análises como ADJ | 302 | 20.45% | 162 | 18.99% | 66 | 24.09% | 74 | 21.14% |
| Análises como ADV | 36 | 2.44% | 26 | 3.05% | 3 | 1.09% | 7 | 2.00% |
| Análises como GRAM | 25 | 1.69% | 19 | 2.23% | 3 | 1.09% | 3 | 0.86% |
| Análises como INTERJ | 16 | 1.08% | 10 | 1.17% | 2 | 0.73% | 4 | 1.14% |
| Análises como PROP | 45 | 3.05% | 19 | 2.23% | 14 | 5.11% | 12 | 3.43% |
| Análises como NUM | 12 | 0.81% | 6 | 0.70% | 1 | 0.36% | 5 | 1.43% |
| Análises da variante lus | 43 | 2.91% | 25 | 2.93% | 1 | 0.36% | 17 | 4.86% |
| Análises da variante bras | 92 | 6.23% | 56 | 6.57% | 12 | 4.38% | 24 | 6.86% |
| Análises raras | 108 | 7.31% | 70 | 8.21% | 13 | 4.74% | 25 | 7.14% |
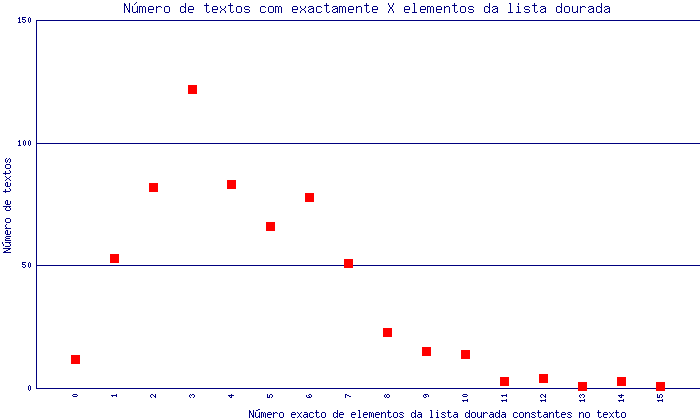
A figura seguinte caracteriza agora os textos em termos de número exacto de formas da lista dourada que incluem.
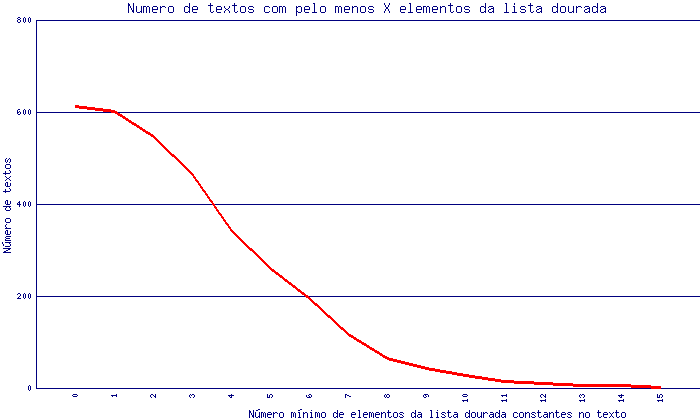
Finalmente os mesmos dados são apresentados de forma acumulada na figura seguinte, que representa o número de textos com pelo menos X elementos da lista dourada.